[Pandas] Series 생성자의 파라미터 data=, index=, name= 활용 방법
많은 양의 데이터를 관리하거나 조회할 때 표(table)는 매우 유용하다. 표 형식의 데이터를 하나의 변수에 저장하기 위해서 Pandas의 Series와 DataFrame을 사용한다. 주로 사용하는 것은 DataFrame이며, DataFrame을 이용하기 위해 Series를 먼저 공부하는것이 유용하다.
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.html
pandas.Series — pandas 1.0.3 documentation
Values must be hashable and have the same length as data. Non-unique index values are allowed. Will default to RangeIndex (0, 1, 2, …, n) if not provided. If both a dict and index sequence are used, the index will override the keys found in the dict.
pandas.pydata.org
위의 pandas 문서에서 확인해보면 Series 생성자의 매개변수는 다음과 같이 6가지인 것을 알 수 있다.
class pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
이 중 data, index, name 파라미터에 대해 여러 가지 예제를 통해 알아보자.
1. data 파라미터
1.1. 시리즈(Series)에 데이터 입력하기
Padas에서 시리즈(Series)란 1차원 배열과 비슷한 데이터 형식이다. 우리가 주로 사용하는 데이터는 1차원 혹은 2차원 배열이다.
<1차원 배열의 예>
아래의 두 가지 표는 1차원 배열의 예시이다. 하나의 열로 데이터가 나열된 것이 특징이다.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 사과 |
| 배 |
| 바나나 |
| 파인애플 |
| 체리 |
<2차원 배열의 예>
아래의 표는 2차원 배열의 예시이다. 행과 열로 구분되어 '데이터의 개수 = 행 x 열'이 되는 것을 알 수 있다.
| 점수 | |
| 국어 | 100 |
| 영어 | 80 |
| 수학 | 90 |
| 사회 | 80 |
| 과학 | 90 |
| 현재가 | 영업이익 | 배당성향 | PER | PBR | DPS | EPS | |
| 삼성전자 | 49,800 | 277,685 | 44.73 | 17.63 | 1.49 | 1,416 | 3,166 |
| SK텔레콤 | 215,500 | 11,100 | 82.04 | 21.59 | 0.78 | 10,000 | 11,021 |
| 기업은행 | 7,300 | 22,279 | 23.83 | 4.93 | 0.35 | 670 | 2,393 |
1.1.1. 변수에 시리즈 데이터를 입력하는 방법(1) - 매개변수 명시
그림 1은 pandas 패키지의 시리즈 생성자(Constructor) 함수를 사용하는 예이다. import pandas as pd를 통해 pandas 패키지명을 pd로 대체해 사용한다고 선언했다. pd.Series()는 pandas 패키지 안에 있는 Series를 생성하는 함수를 사용하겠다는 의미이다. 괄호 안에는 파라미터(매개변수)를 입력해주면 된다.
data 파라미터는 시리즈에 어떤 데이터를 넣을것이냐를 지정해주는 것이다. 데이터를 입력하는 방법은 1.1.1.과 1.1.2. 두 가지 방법이 있다. 1.1.1.과 1.1.2.의 차이는 'data='를 입력했는지의 여부이다. 'data='를 입력한 뒤 추가할 데이터를 입력하면 매개변수를 명시해서 값을 전달하는 것이고, 'data='를 입력하지 않고 데이터를 입력한다면 매개변수를 명시하지 않고 값을 전달하는 것이다.
그림 1의 실행 결과는 그림 2와 같다.


1.1.2. 변수에 시리즈 데이터를 입력하는 방법(2)
1.1.1.에서는 시리즈 생성자의 매개변수 'data='를 명시했다. 그러나 1.1.2.에서는 매개변수 명시를 하지 않고 값만 전달해주었다. 이 둘의 차이는 후에 서술하도록 하겠다(둘의 차이는 4. 매개변수를 명시한 것과 그렇지 않은 것의 차이.
그림 3은 'data='를 생략하고 생성자 함수에 매개변수 값을 전달했다. 'data='를 입력해주는 것과 입력하지 않는것의 차이는 아직까지는 확인할 수 없다. 리스트 형식으로 1, 1, 1을 입력한 결과는 그림 2, 그림 4와 같이 동일하기 때문이다.


1.1.3. 더 많은 데이터를 입력하기
대괄호([ ]) 안에 쉼표로 구분해서 데이터를 무한정 입력할 수 있다. 엑셀에 비해 데이터가 비교적 많아도 데이터를 처리할 수 있는 속도가 월등히 빠르다. 엑셀은 수만줄~수십만줄의 데이터가 입력되어 있는 경우 파일을 여는데도 시간이 엄청나게 오래 걸리고, 스크롤을 하는데 버벅이기도 한다.


1.1.4. 문자 입력
시리즈에는 정수 외에도 실수, 문자 입력도 가능하다. 문자를 입력하고자 한다면 작은따옴표(' ') 안에 문자 혹은 문자열을 입력하면 된다.


2. index 파라미터
2.1. index의 필요성
시리즈를 생성하면 하나의 열로 데이터가 생성이 되는 것을 확인했다. 그러나 시리즈가 저장된 변수를 출력해보면 왼쪽에 0부터 숫자가 순차적으로 부여되며 총 2열이 출력된다. 왼쪽의 숫자가 매겨진 열을 인덱스(index)라고 한다. 그림 9처럼 한 개 열의 데이터를 저장한 뒤, 다시 꺼내오려면 기준되는 점이 필요하다. 그 기준의 역할을 하는 것이 인덱스이다.


반대로 그림 10처럼 인덱스가 없다고 생각해보자. 인덱스가 없다면 for문으로 데이터를 출력할 때 곤란함을 겪을 수 있다. 시리즈에서는 그나마 곤란함이 덜하겠지만 나중에 살펴볼 데이터프레임(DataFrame)에서는 더 큰 문제가 발생할 수 있다. 예를 들어 2행 2열에 10이라는 값이 저장되어있고, 400행 10열에도 10이라는 값이 있다고 하자. 2행 2열의 10 값을 바꾸려고 하는데 인덱스가 없다면 10이라는 값을 한개만 골라서 다른 값으로 바꾸거나 삭제하는 등의 작업을 하기가 매우 어려워진다.

2.2. index 값을 전달하는 예
그림 12는 index 파라미터를 명시해 값을 전달하는 예제이다. index 파라미터 전달 값 첫 번째는 공백으로 두었다. 아래 표에 따라 '전화번호'라는 문자열도 시리즈에 포함시켰기 때문에 '전화번호' 왼쪽의 비어있는 칸을 만들기 위해 공백을 두었다. 전화번호가 들어가는 열에 '전화번호'라는 문자열이 들어가 있기 때문에 같은 성격의 데이터가 들어갔다고 할 수 없다. 이것에 대한 해결책은 3. name 파라미터에서 다루도록 하겠다.
index 파라미터에 리스트를 집어넣으면 리스트의 순서대로 인덱스에 값이 매겨진다(그림 13).
| 전화번호 | |
| 집 | 02-1324-4551 |
| 휴대전화 | 010-4569-4312 |
| 회사 | 070-4143-5327 |
<표 1>


그러나 data의 개수와 index의 개수를 일치시키지 않으면 에러가 발생한다(그림 14, 15).


ValueError: Length of passed values is 3, index implies 2. - 값은 3개이나, 인덱스는 2개로 되어있어 에러가 발생했다는 의미이다(그림 15).
인덱스 파라미터 index= 뒤에 값을 넣어주지 않으면 에러가 발생한다(그림 16, 17).


인덱스를 디폴트(default)로 하려면 index= 구문을 삭제하면 된다.


3. name 파라미터
3.1. 시리즈에 이름 부여하기
2.2. 'index의 값을 전달하는 예'의 <표 1>에서 전화번호 데이터들의 속성을 구별하기 위해 '전화번호'라는 데이터를 맨 윗줄에 추가했다. 그러나 '전화번호'와 '02-1324-4551'은 같은 성격의 데이터가 아니므로 많은 양의 데이터가 있을 때 '전화번호'라는 문자열은 불필요한 값이며 에러를 발생시킬 수 있다. name은 시리즈 데이터의 속성명을 부여할 때 사용하는 파라미터이다. name='전화번호'를 시리즈 파라미터에 추가해주면 s2 시리즈의 이름이 '전화번호'가 된다.
참고로 시리즈를 이용해 데이터프레임을 만들게 되면 '전화번호'라는 name 파라미터 문구가 <표 1>처럼 전화번호의 맨 위쪽에 속성명으로 자리잡게 된다.


4. 매개변수를 명시한 것과 그렇지 않은 것의 차이
4.1.1. 매개변수 명시
매개변수 data=, index=, dtype=, name=, copy=, fastpath 등을 명시한 경우를 먼저 살펴보자(그림 21, 22, 23). 그림 21과 그림 22는 같은 코드이다. 단지 줄바꿈을 했을 뿐이다. 결과는 그림 23과 같은데 인덱스에는 스마트폰 제조사, 데이터에는 스마트폰 명칭이 들어가있다. 참고로 인덱스를 아래와 같은 방식으로 쓰는 것은 바람직하지는 않다. 인덱스 값과 그에 해당하는 데이터 값을 비교해 시리즈를 합치는 등의 연산을 해야하는데 인덱스의 내용이 중복된다면 데이터를 자유롭게 조작하지 못 할 것이다.

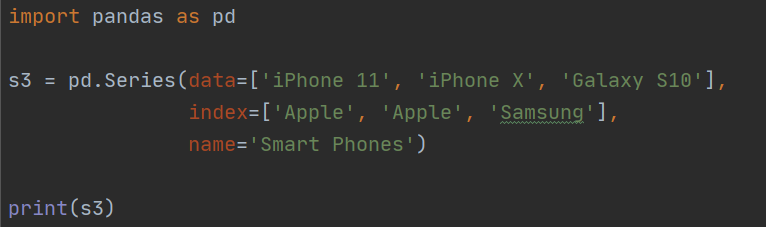

4.1.2. 매개변수 삭제
그림 21의 코드에서 data=, index=, name= 세 개의 코드를 삭제한 뒤 실행하면 오류가 난다(그림 24, 25).
TypeError가 출력된다.


다시 pandas 문서의 Series 생성자 매개변수를 살펴보자. Series에는 6개의 매개변수가 들어간다. 한 개도 누락시키지 않고 작성한다면 그림 27과 같이 작성해야 한다. 그림 27과 같이 작성한 후 프로그램을 실행하면 그림 28의 결과가 나타난다. 그림 21, 22의 결과와 동일하다.



매개변수를 명시하지 않는 경우에는 매개변수의 전달값을 누락시키지 않고 모두 전달해야 한다(그림 30). 전달해야 하는 변수가 무엇인지는 IDE 상에서도 표시가 된다(그림 29). 필자는 PyCharm IDE를 사용한다. 6개의 매개변수를 모두 전달하면 오류가 없이 정상적으로 프로그램이 실행된다(그림 31).



그렇다면 매개변수를 명시하는 것의 장점은 무엇일까? 두 가지의 장점이 있다고 할 수 있다.
첫번째는 내가 사용하고자 하는 매개변수 값만 입력해줄 수 있다는 것이다. 누락된 매개변수는 기본값으로 전달이 된다. 매개변수 기본값은 그림 26, 29를 보면 알 수 있다.
1. data 값을 넣어주지 않으면 None이 전달된다.
2. index 값을 넣어주지 않으면 None이 전달된다.
3. dtype 값을 넣어주지 않으면 None이 전달된다.
4. name 값을 넣어주지 않으면 None이 전달된다.
5. copy 값을 넣어주지 않으면 False가 전달된다.
6. fastpath 값을 넣어주지 않으면 False가 전달된다.
두 번째로는 매개변수 전달 순서를 지키지 않아도 된다는 것이다. 그림 32를 보면 매개변수가 name, index, data 순으로 입력된 것을 볼 수 있다. 그럼에도 불구하고 위의 예시들과 동일하게 시리즈가 작성되는 것을 확인할 수 있다.


'IT > Python' 카테고리의 다른 글
| import pandas as pd, import numpy as np 등 as **를 쓰는 이유 (0) | 2020.04.23 |
|---|---|
| [Pycharm] 파이참(파이썬 IDE) 설치, pip 모듈 설치, 기본 사용방법 (1) | 2020.04.21 |
